CorCTF 2025

This writeup is my individual effort in solving rev challenges from corCTF as part of Team Shellphish. This was my first time playing with Shellphish and we finished 14th overall 💪 .
I'm mainly focused on rev challenges in this CTF and managed to solve yourock and tagme. I got partial flag for roll_vm as well but gave it another try after the CTF and got the flag! Other than this my teammates also solved boat_vm and I'll add it's writeup here once I find time to solve it personally.
This writeup is a bit comprehensive because I'll discuss not only the final solution but also my thought process while reversing during the CTF. Having said that let's dive in:
Challenge #1: yourock
Category: rev
Author: jazz
Challenge prompt:
Forget Enigma, forget Caesar. The only cipher you need is 2009's infamous password dump.
Challenge handout has two files inside, one of them is a target ELF named encode and the other one is an encrypted file named encoded.rj. Before we begin decompilation let's see what happens when we run the program:
Usage: ./encode "your message"So the program expects a string, let's try a random string for now:
Failed to open ./rockyou.txtSo the program needs rockyou.txt to be in the same directory, I'm guessing it uses it to encode the input string. This is also explains what the challenge prompt is referring to "The only cipher you need is 2009's infamous password dump."
So after placing rockyou.txt in the same directory, we pass in a string "random":
cosmos@cosmos-VirtualBox:~/workspace/corctf/yourock$ ./encode random
Encoded output:
hellokitty 00000 qwerty lovely 12345678 12345678 1234567If we compare this with our encoded.rj file, we can see that both of them have a similar format, where the encoded output has words separated by a space. I think it is safe to assume that the encoded.rj file is encoded output of the flag when it was ran against the given program.
Another interesting thing to notice is that the number of words in the encoded output is always 1 more than the length of the input string, this suggests that the encode program could be doing some kind of byte-by-byte operation on the input string outputting an extra word with it.
DECOMPILATION
Let's look at the program decompilation in IDA:
std::allocator<char>::allocator(&wordlist_map, argv, a3);
std::string::basic_string<std::allocator<char>>(&input, argv[1], &wordlist_map);
std::allocator<char>::~allocator(&wordlist_map);
std::vector<std::string>::vector(&wordlist_lines);
std::unordered_map<std::string,unsigned long>::unordered_map(&wordlist_map);
if ( (unsigned __int8)load_file(&wordlist_lines, &wordlist_map) != 1 )Looking at this we can safely say that this is a C++ binary and at first it can be hard to read, but let's try to dig in and see what the binary is trying to do.
So the binary allocates an empty string vector named wordlist_lines and an unordered map named wordlist_map. If you don't know what an unordered map is, you can think of it as a python dictionary which holds values in key-value pairs as they are both implementations of hash maps.
Encoding
Upon successfully opening rockyou.txt it generates a key using generate_key and encodes the given string using encode function which takes 4 args.:
- encoded_words (empty vector for now)
- input (input string)
- wordlist_lines (vector containing all passwords from rockyou.txt)
- key (generated from generate_key)
And after execution of this function the binary prints out the encoded_words buffer separated by a space.
Let's look inside the encode function first:
std::vector<std::string>::vector(encoded_words);
word = std::vector<std::string>::operator[](wordlist_lines, key);
std::vector<std::string>::push_back(encoded_words, word);
for ( i = 0LL; i < std::string::size(input); ++i )
{
xored_byte = key ^ *(_BYTE *)std::string::operator[](input, i);
if ( xored_byte >= (unsigned __int64)std::vector<std::string>::size(wordlist_lines) )
exit(1);
new_line = std::vector<std::string>::operator[](wordlist_lines, xored_byte);
std::vector<std::string>::push_back(encoded_words, new_line);
key ^= i ^ xored_byte;
}
return encoded_words;If you're having trouble reading the decompiled C++ source code in IDA,
you can rename functions and then think of the first arg as the vector
the operation is performed on.
For example:
std::vector<std::string>::push_back(encoded_words, word);
this decomp maps to this in the actual C++ source code:
encoded_words.push_back(word); so the encode function boils down to this:
- It takes the key and uses it as an index in the wordlist_lines array, grabs the word from that index and puts that word into the encoded_words array. (This is the reason why we always have an extra word in the encoded output)
- After that it kicks off a loop based on the size of the input string, and XOR's every byte of the input string with the key.
- Then it uses the XOR'ed value as an index into the wordlist array and puts that word into the encoded words array.
- Then it updates the key by XOR'ing it with the index and the xored_byte variable
Updating the key is a simple XOR operation which can be reversed if we know the index i and the xored_byte, we already know i but the xored_byte depends on the initial key. So all we need to break this encoding is the initial key, let's see how that is being generated.
Key generation
Key generation is pretty simple, we take a time-based seed and feed it to srand and then generate a random number from it. But we compute the modulus of it with 256 means that the returned value will be within the range [0, 255]
__int64 __fastcall generate_key(__int64 *a1)
{
unsigned int v1; // eax
v1 = time(a1);
srand(v1);
return (unsigned int)(rand() % 256);
}Since our key is used as an index in the wordlist array, it means that our initial word will always be within the first 255 words of rockyou.txt. So basically given an encoded output we just need to find the index of the first encoded word and that will be our key.
Looking at encoded.rj the first word is charlie, let's look for its index in rockyou.txt
head -n255 rockyou.txt | cat -n | grep charliethe output comes out to be 64 charlie, but since this is 1-indexed we can set our key as 63.
Solution
Now that we know our initial key we can reverse the XOR operation and get the actual string back, While encoding the input string we did:
xored_byte = input[i] ^ key
so to reverse this we just need to do:
input[i] = xored_byte ^ key
This is the final solve script:
with open("encoded.rj") as fp:
encoded = fp.read().strip()
encoded_words = encoded.split(" ")
print(encoded_words)
flag = ""
with open("rockyou.txt", encoding='utf-8', errors="ignore") as fp:
pwds = [line.strip() for line in fp]
key = pwds.index(encoded_words[0])
encoded_words = encoded_words[1:]
for i in range(len(encoded_words)):
xored_byte = pwds.index(encoded_words[i])
flag += chr(key^xored_byte)
key ^= i^xored_byte
print(flag)And we get the flag: corctf{r0cky0u_3nc0d1ng_r0cks} 🎉
Challenge #2: tagme
Category: rev
Author: maxster
We are greeted with a dynamically linked, stripped binary. Classic crackme style challenge which takes in a input string and validates it, our input is also our flag.
Looking at the binary in IDA the binary isn't completely stripped, libc functions are there, but we still need to make sense of some functions and rename them:
void __fastcall __noreturn main(int a1, char **a2, char **a3)
{
char v3; // [rsp+3h] [rbp-3Dh]
char *lineptr; // [rsp+8h] [rbp-38h] BYREF
size_t n; // [rsp+10h] [rbp-30h] BYREF
unsigned __int64 i; // [rsp+18h] [rbp-28h]
__ssize_t v7; // [rsp+20h] [rbp-20h]
char *v8; // [rsp+28h] [rbp-18h]
unsigned __int64 v9; // [rsp+30h] [rbp-10h]
unsigned __int64 v10; // [rsp+38h] [rbp-8h]
v10 = __readfsqword(0x28u);
puts("Enter flag:");
lineptr = 0LL;
n = 0LL;
v7 = getline(&lineptr, &n, stdin);
if ( v7 == -1 )
sub_1209("Illiterate");
if ( v7 <= 8 )
sub_1209("Short");
if ( v7 > 39 )
sub_1209("Long");
if ( strncmp("corctf{", lineptr, 7uLL) )
sub_1209("Ineligible");
if ( strncmp("}\n", &lineptr[v7 - 2], 2uLL) )
sub_1209("Ineligible");
sub_126D();
v8 = lineptr + 7;
v9 = v7 - 9;
for ( i = 0LL; i < v9; ++i )
{
v3 = v8[i];
if ( (i & 1) != 0 )
{
if ( i % 6 > 3 )
{
if ( v3 <= 112 )
sub_1209("Forbidden");
}
else if ( v3 <= 107 || v3 == 115 )
{
sub_1209("Forbidden");
}
}
else if ( v3 == 99 || v3 > 108 )
{
sub_1209("Forbidden");
}
sub_12A4((unsigned int)v3);
}
while ( !(unsigned int)sub_13F8() )
;
sub_1209("Boring");
}We take input from stdin using getline, which returns the number of chars taken input. This means that v7 has the flag_length and lineptr is basically a pointer to the input string.
v8 is flag_ptr + 7, since flag format starts with corctf{, v8 basically points to the first character inside the brackets aka the flag_bytes. v9 is v7 - 9 and since v7 was our flag_length, v9 is the length of our flag_bytes which is the string inside the brackets.
By the looks of it sub_1209() looks like some kind of fail condition function, since it prints Rejected and exits the program.
void __fastcall __noreturn sub_1209(const char *a1)
{
printf("%s\nRejected\n", a1);
exit(1);
}We'll rename sub_1209 to fail for now. We can also rename v8 and v9 to flag_chars and flag_len based on what we discussed above.
Looking at the for loop, we loop until the end of the input string and store the current byte in v3. We can rename v3 as flag_byte. Now if we look inside the for loop it is laid out with traps which instantly trigger the fail condition, if we manage to avoid these we get to a function named sub_12A4
Now let's look at this other function sub_12A4:
__int64 __fastcall sub_12A4(char a1)
{
__int64 result; // rax
byte_4060[qword_4048] = a1;
if ( ++qword_4048 == 4600 )
qword_4048 = 0LL;
result = qword_4040;
if ( qword_4048 == qword_4040 )
sub_123B("Interesting");
return result;
}If we manage to avoid the traps, we pass the flag_byte as input to this function which writes it to a global buffer byte_4060. The index is decided by another value stored in the .bss qword_4048. This global buffer is interesting because it writes upto size 4600 and then loops back around to the start of the buffer by setting the index pointer to 0.
This means that byte_4060 is some kind of circular buffer with length 4600. We also take another pointer qword_4040 and compare it with our index pointer. If these two pointers match then we take this other function sub_123B and if we look inside it we can see that it prints Accepted and exits. This clearly means that this is our success case and we have to somehow reach here to get the flag!
So based on all of this we can re-define:
- byte_4060 to circular_buffer
- qword_4048 to write_ptr
- qword_4040 to read_ptr
- sub_123B to success
There's another interesting function in a while loop at the end, let's uncover that:
__int64 sub_13F8()
{
size_t j; // rax
char v2; // [rsp+Ah] [rbp-26h]
char v3; // [rsp+Bh] [rbp-25h]
int i; // [rsp+Ch] [rbp-24h]
size_t v5; // [rsp+10h] [rbp-20h]
__int64 v6; // [rsp+18h] [rbp-18h]
char *s; // [rsp+28h] [rbp-8h]
if ( (unsigned int)sub_138A() )
return 1LL;
v2 = sub_1318();
v6 = sub_13AB((unsigned int)v2);
if ( v6 == -1 )
fail("Bizzare");
for ( i = 1; i <= 1; ++i )
{
if ( (unsigned int)sub_138A() )
return 1LL;
v3 = sub_1318();
if ( sub_13AB((unsigned int)v3) == -1 )
fail("Bizzarre");
}
s = (char *)*((_QWORD *)&unk_3CE0 + 2 * v6 + 1);
v5 = 0LL;
for ( j = strlen(s); v5 < j; j = strlen(s) )
sub_12A4(s[v5++]);
return 0LL;
}If we look at sub_1318, we check if our write_ptr is the same as qword_4040. If not we use the qword_4040 to read values from the circular_buffer and return it. From this we can rename qword_4040 to be our read_ptr
__int64 sub_1318()
{
unsigned __int8 v1; // [rsp+Fh] [rbp-1h]
if ( qword_4040 == write_ptr )
fail("Dry");
v1 = circular_buffer[qword_4040];
if ( ++qword_4040 == 4600 )
qword_4040 = 0LL;
return v1;
}This also makes sense because at the start of the function, we check if read_ptr and write_ptr are not same, otherwise it would mean that the buffer is empty. From this we can also rename sub_138A to is_buffer_empty as it does the same. We can also rename sub_1318 to circular_buffer_read.
Making Custom Structs in IDA
Now let's look at sub_13AB:
__int64 __fastcall sub_13AB(char a1)
{
unsigned __int64 i; // [rsp+Ch] [rbp-8h]
for ( i = 0LL; i <= 9; ++i )
{
if ( a1 == *((_BYTE *)&unk_3CE0 + 16 * i) )
return i;
}
return -1LL;
}This is comparing a1(char from circular_buffer_read) to a dereferenced value from the global buffer/struct. But it's hard to read like this:
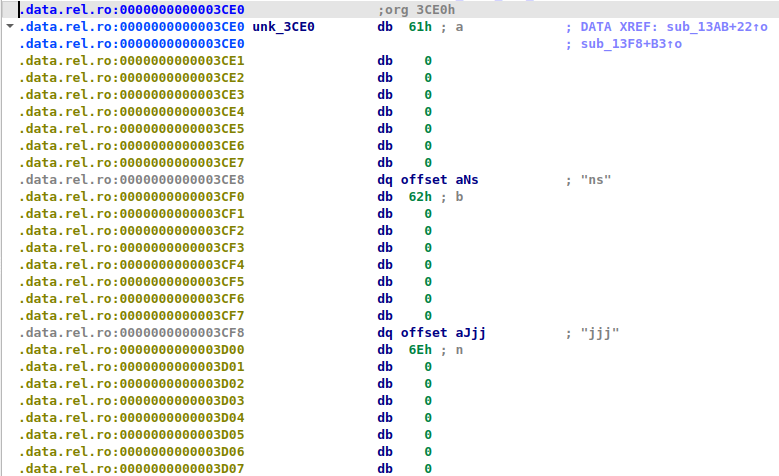
But looking at this we can see a clear defined structure, so let's go ahead and make a custom struct for this so it is more readable. So every entry has:
- 1 byte char
- 7 null bytes
- pointer to a string in .rodata (double-click aNs or aJjj to check)
Let's go over to Local types and make this struct:
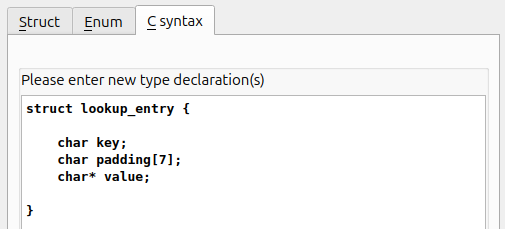
we save this and we go over to our data in the global section and we hit y on the unk_3CE0 to change it's type to lookup_entry[10]; since we have 10 entries in total. And BOOM! we get a much more readable version:
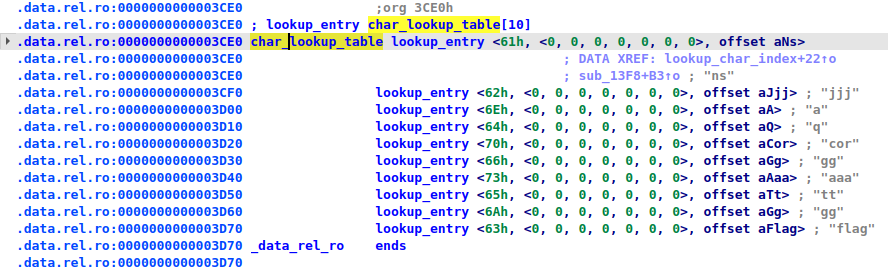
From this we can get this mapping:
a ---> "ns"
b ---> "jjj"
c ---> "flag"
d ---> "q"
e ---> "tt"
f ---> "gg"
j ---> "gg"
n ---> "a"
p ---> "cor"
s ---> "aaa"So if we look closely, the code takes each byte of input and checks it against the keys in this struct, if they don't match, it immediately reverts to a fail case and exits the program. So using this we've constrained our flag_bytes to only these 10 characters.
If we look further into the function it does circular_buffer_read twice that means it gets the current and the next flag_byte, but it only uses the flag_byte at the current index to modify the input string.
s = char_lookup_table[char_index].value;
v5 = 0LL;
for ( j = strlen(s); v5 < j; j = strlen(s) )
circular_buffer_write(s[v5++]);This piece of code just appends the value from the lookup_table to the end of the input string. So if our string was anp (assuming we pass the checks in our main function), it would become:
anp --------> npns
npns -------> pnsa
pnsa -------> nsacor
nsacor -----> sacora
sacora -----> acoraaaa
acoraaaa ---> coraaaans
coraaaans --> oraaaansflag
oraaaansflag --> Invalid ❌ Thinking about this we can rule out some more characters from our lookup_entry table as they'll lead to bad input characters i.e. characters which our not present in the lookup table after expansion. Therefore:
Bad input chars: ['b', 'c', 'd', 'e', 'f', 'j', 'p']
Good input chars: ['a', 'n', 's']
Now if we go back and look at the constraints present in the main function, we can maybe shorten our search space even more. The constraints in the main function are for odd/even indices and can be summarized like this:
There are only 3 types of possible input chars, if we hold the above assumption of good chars. to be true:
Odd1 indices ---> [1, 3, 7, 9, 13, 15...]
these can only have char "n"
Odd2 indices ---> [5, 11, 17...]
these can only have char "s"
Even indices ---> [0, 2, 4, 6...]
these can only have char "a"Now that we know which indices can have which chars. we still need to know the length of the flag, but we can just try every flag length up to 30 and one of them should be correct. So we just write a simple script which does that.
Final solve script
from pwn import *
PREFIX = "corctf{"
SUFFIX = "}"
def generate_flags(len):
candidate = []
for i in range(len):
if i%2 == 0:
candidate.append("a")
elif i % 6 > 3:
candidate.append("s")
else:
candidate.append("n")
return f"{PREFIX}{''.join(candidate)}{SUFFIX}"
for i in range(31):
flag = generate_flags(i)
with process("tagme", level="CRITICAL") as p:
p.sendline(flag)
out = p.recvall()
if b'Accepted' in out:
print(out)
print(flag)Flag: corctf{ananasananasananasananasana} 🎉
Challenge #3: Roll VM
Category: rev
Author: maxster
This CTF was all about VM's and I'm not particularly good with VM's, in fact this is the first VM challenge I've ever solved in a CTF! So I'll discuss my approach for this one in-depth.
Loading this program in IDA we directly drop into the start function and even though most of the function names are stripped looking at it we can rename the functions inside it as __libc_start_main which then calls the main function.
Looking at the main function we can see a function with an error statement as the input, we can go ahead and rename this as puts and the function after it as exit as it is a common pattern to end the program in error cases.
After this there is a small do-while loop which gets triggered when we enter 10 arguments which is just a ragebait function so we'll just skip it because it probably just leads us to a fake flag.

Instead let's look into sub_401ED0 which takes argv[1] as input:
__int64 __fastcall sub_401ED0(__int64 a1)
{
__int64 v1; // rax
__int64 v2; // rbp
__int64 v3; // rbx
__int64 v4; // rax
char *v5; // r12
char *v6; // rdx
__int64 v7; // rcx
unsigned int v8; // eax
v1 = sub_405890(a1, "rb");
if ( !v1 )
{
puts("Failed to open file");
exit(1LL);
}
v2 = v1;
sub_407B70(v1, 0LL, 2LL);
v3 = sub_405B00(v2);
sub_408000(v2);
v4 = sub_413180(v3);
v5 = (char *)v4;
if ( !v4 || (sub_405990(v4, 1LL, v3, v2), qword_4ACB20 = v3, (qword_4ACB28 = sub_4142A0(v3, 1LL)) == 0) )
{
puts("Failed to allocate required data");
exit(1LL);
}
if ( v3 <= 0 )
{
v7 = 0LL;
}
else
{
v6 = v5;
v7 = 0LL;
do
{
v8 = *v6 - 97;
if ( v8 <= 0x12 )
*(_BYTE *)(qword_4ACB28 + v7++) = v8;
++v6;
}
while ( &v5[v3] != v6 );
}
qword_4ACB20 = v7;
return sub_413850(v5);
}Looking at the function arguments for sub_405890 we can confidently say that it's fopen since a1 is the filename being passed. We can also rename types of v1 and v2 to FILE *. Now looking at sub_407B70, it takes 3 args, a file_ptr, 0 and 2. My best guess is that this is fseek which also takes 3 args of the same type and the 3rd arg. 2 corresponds to SEEK_END which seeks to the end of the file.
The next function sub_405B00 is probably ftell as it takes v2 (a file_ptr) as an argument and returns the number of bytes from the start of the file stream, this is probably done to get file_size in bytes.
Next up we use sub_408000 and pass the file_ptr which I think is rewind to go back to the starting of the file stream.
After this we pass v3 which holds file size in bytes to sub_413180. Since this takes only 1 argument, this is probably malloc to allocate a buffer to store contents of the file.
Next up is sub_405990 which I think is probably fread based on the type of arguments passed, you can double check them using man fread.
And the next one is probably calloc since it takes file_size and another argument and allocates a buffer (the print statement inside the function gave this one away).
qword_4ACB20 and qword_4ACB28 are two values in the .bss which hold file_size in bytes and the vm_code loaded from the file passed as argv[1]
Next it runs a while loop where it iterates over byte in the vm_code and subtracts it by 97 and stores it back. Now we can rename this parent function sub_401ED0 as read_vmcode since it reads the bytecode from the provided file.
There's another function next to it which defines a bunch of global variables and buffers but there role still isn't clear so we'll just call it vm_init for now.
This reversing part may be boring for a seasoned CTF player but I felt it was important to include in the writeup as it might help some new CTF player think about how to approach stripped binaries. Though most of these were educated guesses a better alternative approach is to apply a FLIRT signature in IDA and recover most of the libc functions.
VM Reversing
Now we're getting into the juicy part, reversing any VM requires us to identify the instruction pointer, number of registers, the opcodes and their functionality. So let's do that:
Right off the bat we can see a lot of xmm registers, these are floating point registers which are 128-bit long registers and can be used in a lot of ways, in our case they are used to hold two 64-bit values suggested by this repeating pattern:
v10 = *((_QWORD *)&xmmword_4ACB50 + 1);The register xmmword_4ACB40 hold two 64-bit values, in this case v10 is accessing the higher 64 bits while in the snippet below the lower 64 bits are being set to v10.
*(_QWORD *)&xmmword_4ACB40 = v10;From the code snippet below we can deduce that xmmword_4ACB40 is the program counter (instruction pointer) pc since we exit the VM once pc reaches file_size:
if ( (unsigned __int64)xmmword_4ACB40 >= file_size )
{
LABEL_9:
puts("VM error");Looking at the switch case in the VM we can also deduce that every instruction in the VM is a fixed 1-byte instruction since we use v3 as the iterator on the vm_code to go over every byte.
switch ( *(_BYTE *)(vm_code + v3) )Now if we look closely in all of the switch cases we use these 2 variables to get or set values, xmmword_4ACB40 and xmmword_4ACB50. But we just established that these are 128-bit registers and keeping in mind that xmmword_4ACB40 is our pc that means we have 4 registers in total:
- xmmword_4ACB40 which is pc
- xmmword_4ACB40 + 8 which is reg_a
- xmmword_4ACB50 which is reg_b
- xmmword_4ACB50 + 8 which is reg_c
Now we can rename things and make a local type based on this information to make our code much more readable, because of the naming convention we know that these registers are laid out next to each other so we can define a local type like this:
struct vm_state {
unsigned __int64 pc;
unsigned __int64 a;
unsigned __int64 b;
unsigned __int64 c;
};After applying the local type on our decompiled code. it looks so much easier to read and now we can start hunting for opcodes. Some of them are easy giveaways like ADD, SUB, MUL, DIV, the stack opcodes like PUSH and POP can also be easily deduced based on the error messages.
The more interesting ones are opcodes 0x0 and 0x1, let's see why:
case 0:
v6 = &vm;
memmove(&vm, &vm.a, 24LL);
v27 = vm.pc;
vm.pc = v27 - 1;
vm.c = pc;
goto LABEL_8;
case 1:
c = vm.c;
v6 = &vm;
memmove(&vm.a, &vm, 24LL);
vm.pc = c;
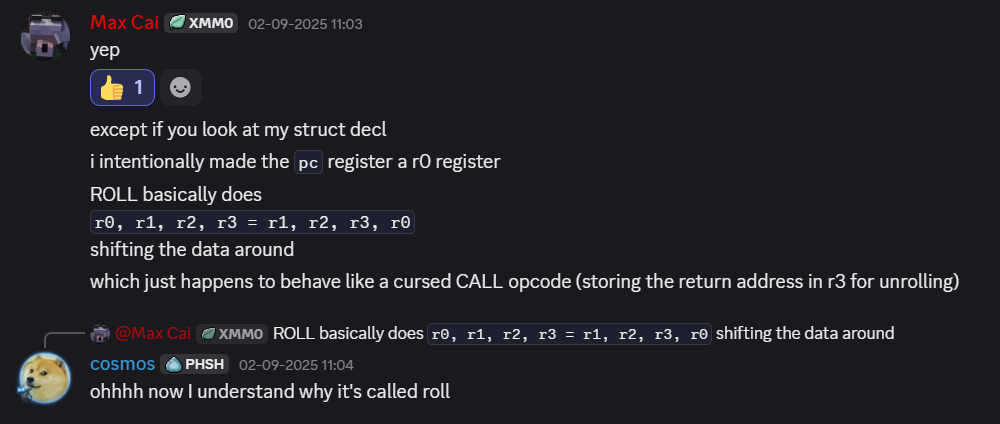
goto LABEL_8;If you remember, registers are mapped next to each other in memory so in opcode 0x0 we use memmove to copy 24 bytes from register a to pc which basically rotates registers state to the left, something like this:
pc, a, b, c = a, b, c, pcand the opposite happens in opcode 0x1 where we basically shift register state to the right:
pc, a, b, c = c, pc, a, bDuring the CTF we named these instructions CALL and RET and emulated the shift correctly but after the CTF ended when I talked to the challenge author I realized this is basically a ROLL and UNROLL operation which made me realize why this challenge is called ROLL VM
VM Emulation
Now that we know all of our opcodes and we also have the bytecode why doesn't the program do anything? 🤔
Let's get the disassembly of the bytecode to find out. To get the disassembly of the bytecode we used our Binja plugin (we literally vibecoded it during the CTF and used it for all 3 VM challenges lol) and fed it instructions and bytecode to get the disassembly. I'll only post a small snippet of it here:
00000000 0b inc
00000001 0d push {var_8}
00000002 02 swap
00000003 0a zero
00000004 0c dec {-0x1}
00000005 02 swap
00000006 08 div
00000007 0d push {var_10}
00000008 0a zero {start}
00000009 0d push {var_18} {start}
0000000a 0b inc {0x1}
0000000b 02 swap
0000000c 0e pop {start}
0000000d 05 add
0000000e 0d push {var_18_1}
0000000f 0a zero
00000010 0b inc
00000011 0b inc {0x2}
00000012 07 mul
00000013 02 swap
00000014 0e pop {var_18_1}
00000015 05 add
00000016 0d push {var_18_2}
00000017 0a zero
00000018 0b inc
00000019 0b inc {0x2}
0000001a 07 mul
0000001b 02 swap
0000001c 0e pop {var_18_2}
0000001d 05 add
0000001e 0d push {var_18_3}
0000001f 0a zero
00000020 0b inc
00000021 0b inc {0x2}
00000022 07 mul
00000023 02 swap
00000024 0e pop {var_18_3}
00000025 05 add
00000026 0d push {var_18_4}
00000027 0a zero
00000028 0b inc
00000029 0b inc {0x2}
0000002a 07 mul
0000002b 02 swap
0000002c 0e pop
0000002d 02 swap
0000002e 04 mov
0000002f 0c dec
00000030 0c dec
00000031 0c dec
00000032 0c dec
00000033 0c dec
00000034 07 mul
00000035 02 swap
00000036 0e pop
00000037 07 mul
00000038 02 swap
00000039 0e pop
0000003a 02 swap
0000003b 00 call a
0000003c 12 exitIn the disassembled bytecode I could clearly see that it has a lot of putc instructions, so it is fair to assume that it prints the flag byte-by-byte. But we still see no output from the program which is interesting.
We built an emulator which mirrors the program behavior by parsing the disassembled bytecode from the file but even that was stuck which made us question whether our implementation was wrong or not. So we decided to look into the program behavior in gdb and after importing the local VM struct symbols in gdb (courtesy of rev god x3ero0) we realized that the program is stuck in a very very very long loop (2^63 iterations to be precise) and never gets past it to get into the core of the problem.
So I modified the interpreter to instead start from pc = 0x96 because this is where we set our register state for the first putc instruction and let it rip. Sadly during the CTF we could only manage 3/4th of the flag. Because the flag was divided into 4 parts, we got everything except the 3rd part of the flag (I probably emulated some instructions wrong).
Final solve script
But after the CTF ended I decided to approach this challenge from scratch again, and after writing the new emulator I got the flag in one go!
from __future__ import annotations
import argparse
import re
import sys
from dataclasses import dataclass
from typing import List, Optional
U64_MASK = (1 << 64) - 1
STACK_MAX = 0x800
# Numeric opcodes (from the BN dump)
CALL = 0x00 # ROLL
RET = 0x01 # UNROLL
SWAPAB = 0x02
SWAPAC = 0x03
MOV = 0x04 # MOV_A_B
ADD = 0x05
SUB = 0x06
MUL = 0x07
DIVU = 0x08
MODU = 0x09
ZERO = 0x0A
INC = 0x0B
DEC = 0x0C
PUSH = 0x0D
POP = 0x0E
GETC = 0x0F
PUTC = 0x10
NOP = 0x11
HALT = 0x12
def u64(x: int) -> int:
return x & U64_MASK
class VMError(RuntimeError):
pass
# ---------- input parsing ----------
BN_LINE = re.compile(r'^([0-9A-Fa-f]{8})\s+([0-9A-Fa-f]{2})\b')
def load_program(path: str) -> List[int]:
with open(path, 'rb') as f:
raw = f.read()
ops = {}
for ln in raw.decode('utf-8', 'ignore').splitlines():
m = BN_LINE.match(ln)
if not m:
continue
addr = int(m.group(1), 16)
byt = int(m.group(2), 16)
ops[addr] = byt
if not ops:
raise VMError("No opcodes parsed from BN text. Wrong file/format?")
max_addr = max(ops)
code = [ops.get(i, NOP) for i in range(max_addr + 1)]
return code
# ---------- VM core ----------
@dataclass
class State:
pc: int = 0
a: int = 0
b: int = 0
c: int = 0
stack: List[int] = None
def __post_init__(self):
if self.stack is None:
self.stack = []
class RollVM:
def __init__(self, code: List[int]):
self.code = code
self.N = len(code)
self.st = State()
# Helpers
def _push(self):
if len(self.st.stack) >= STACK_MAX:
raise VMError("Stack overflow")
self.st.stack.append(u64(self.st.a))
def _pop(self):
if not self.st.stack:
raise VMError("Stack underflow")
self.st.a = self.st.stack.pop()
def _getc(self) -> int:
b = sys.stdin.buffer.read(1)
return 0xFFFFFFFF if not b else b[0]
def _putc(self, byte_val: int):
sys.stdout.buffer.write(bytes([byte_val & 0xFF]))
sys.stdout.buffer.flush()
# One step
def step(self) -> bool:
pc = self.st.pc
if not (0 <= pc < self.N):
return False
op = self.code[pc]
next_pc = (pc + 1) % self.N # default linear advance
if op == CALL:
# Rotate left: (pc,a,b,c) -> (a,b,c,pc), and execute at new pc
old_pc, old_a, old_b, old_c = self.st.pc, self.st.a, self.st.b, self.st.c
self.st.pc, self.st.a, self.st.b, self.st.c = (old_a % self.N), old_b, old_c, old_pc
return True # do not auto-advance
elif op == RET:
# Rotate right: (pc,a,b,c) -> (c,pc,a,b), then continue at pc+1
old_pc, old_a, old_b, old_c = self.st.pc, self.st.a, self.st.b, self.st.c
self.st.pc, self.st.a, self.st.b, self.st.c = old_c, old_pc, old_a, old_b
self.st.pc = (self.st.pc + 1) % self.N
return True
elif op == SWAPAB:
self.st.a, self.st.b = self.st.b, self.st.a
elif op == SWAPAC:
self.st.a, self.st.c = self.st.c, self.st.a
elif op == MOV:
self.st.a = u64(self.st.b)
elif op == ADD:
self.st.a = u64(self.st.a + self.st.b)
elif op == SUB:
self.st.a = u64(self.st.a - self.st.b)
elif op == MUL:
self.st.a = u64(self.st.a * self.st.b)
elif op == DIVU:
den = u64(self.st.b)
if den == 0:
raise VMError("VM error (div by 0)")
self.st.a = u64(u64(self.st.a) // den)
elif op == MODU:
den = u64(self.st.b)
if den == 0:
raise VMError("VM error (mod by 0)")
self.st.a = u64(u64(self.st.a) % den)
elif op == ZERO:
self.st.a = 0
elif op == INC:
self.st.a = u64(self.st.a + 1)
elif op == DEC:
self.st.a = u64(self.st.a - 1)
elif op == PUSH:
self._push()
elif op == POP:
self._pop()
elif op == GETC:
self.st.a = self._getc()
elif op == PUTC:
self._putc(self.st.a)
elif op == NOP:
pass
elif op == HALT:
return False
# fallthrough: advance pc for non-control ops
self.st.pc = next_pc
return True
def run(self, start_pc: int, max_steps: int = 200_000_000):
self.st.pc = start_pc % self.N
steps = 0
while steps < max_steps and self.step():
steps += 1
return steps
def main():
ap = argparse.ArgumentParser(description="roll-vm minimal emulator (distinct implementation)")
ap.add_argument("program", help="BN text dump with byte column OR raw program file")
ap.add_argument("--start", default="0x96", help="start PC (hex or int)")
args = ap.parse_args()
code = load_program(args.program)
start_pc = int(args.start, 0)
vm = RollVM(code)
vm.run(start_pc)
if __name__ == "__main__":
main()Flag: corctf{lfg_i_L0V3_cNtrl_fl0W} 🎉
That pretty much summed up my work in this CTF, I really loved all the rev challenges in corCTF and I'll work on the other two whenever I find time. I'm still a noob CTF player and may have made mistakes in this writeup, feel free to point it out and Happy Hacking! 😃